
Multi-Agent Systems Explained: How AI Agents Work Together
Learn how multi-agent AI systems work, from architecture patterns to real-world applications. Understand the benefits of multi-agent AI architecture, swarms.
Here’s a confession: I didn’t get multi-agent systems at first.
Back in early 2024, I was obsessed with making a single “God-Agent.” I wanted one prompt, one model, and one context window to handle everything from market research to writing deployment scripts. I thought that as models like GPT-4 got smarter, the need for complexity would vanish.
I was dead wrong.
Last month, I was building a system to automate a complex competitive analysis for a client. I tried the single-agent approach again, just to see if GPT-5.2 could handle it. By the time it got to analyzing the third competitor’s pricing strategy, it started “hallucinations” of features that didn’t exist and forgot the formatting requirements I’d set in the initial prompt. The context window was stuffed, the reasoning was muddy, and the output was useless.
Then I broke it down. I created a Research Agent, a Data Synthesis Agent, and a Lead Editor Agent. Suddenly, the quality skyrocketed. The “hallucinations” vanished because each agent had a narrow, manageable task.
That was my “aha” moment. In 2026, building with AI isn’t about finding the biggest model; it’s about building the best team. That’s what we’re diving into today—the world of Multi-Agent Systems (MAS), and why they are the “microservices moment” for artificial intelligence.
What Are Multi-Agent Systems?
If you’ve ever worked in a corporate office, you already understand multi-agent systems. You don’t expect the CEO to write the legal contracts, fix the server, and design the logo. You have specialized departments. The “system” is the collective intelligence of those specialists working toward a common goal.
In technical terms, multi-agent systems are environments where multiple autonomous AI agents interact, communicate, and collaborate to solve problems that are too complex for a single agent.
In 2026, we’ve moved past the “chatbot” era. We’re now in the era of distributed AI systems. Instead of one monolithic model trying to be a jack-of-all-trades, we use orchestrated teams of specialists. According to research from Gartner, it is projected that by 2026, 40% of enterprise applications will feature task-specific AI agents, a massive jump from less than 5% in early 2024.
The Evolution: From Monoliths to Teams
Think about the history of software. We started with monolithic applications where every line of code lived in one giant file. Then we moved to microservices because they were easier to scale, debug, and maintain.
We’re seeing the exact same evolution in AI:
- Stage 1: The Prompt (2022-2023): You send a message, the model responds.
- Stage 3: The Agent (2024): A model with “tools” (like a calculator or search engine) that can take actions.
- Stage 4: Multi-Agent Systems (2025-2026): Orchestrated teams where “Agent A” does the research, “Agent B” writes the code, and “Agent C” reviews everything for security flaws.
Want to understand the foundational shift? Check out our breakdown of how agents differ from chatbots.
Under the Hood: Cognitive Architectures
Before we get into the “how,” we need to talk about the “mind” of the agent. In 2026, we don’t just “prompt” agents; we design their cognitive architectures.
I spent years following the debate between symbolic AI (logic-based) and connectionist AI (neural networks). In a multi-agent system, we finally have the best of both worlds. We use “Neural-Symbolic” architectures where the LLM provides the creative “spark,” but a set of logical constraints (the symbolic part) keeps the agent from wandering off-track.
We’re borrowing heavily from classical AI frameworks like SOAR and ACT-R. These frameworks suggest that intelligence requires a “Global Workspace”—a place where different parts of the “brain” (or in our case, different agents) can post information for others to see. When I’m designing a system, I often think of it as building a collective consciousness. Each agent has its own “inner monologue” (chain-of-thought), but they all contribute to a shared “mental model” of the task.
If you’re an old-school AI researcher, you might find this hilarious—we’re basically rediscovering 1980s AI theories, but we finally have the compute and the models to make them actually work. It’s almost like the agents are following a “Society of Mind” approach, as Marvin Minsky envisioned.
A Day in the Life of a Multi-Agent Team
To really understand how this works, let’s step into a hypothetical “office” of AI agents. I recently set up a system like this to handle my technical blog production. Here’s what happens when I give it a single command: “Write a 4,000-word deep dive into Rust memory safety.”
09:00:00 - The Orchestrator (Planning)
The Orchestrator agent (using Claude 4.5 for its superior planning) receives the request. It doesn’t start writing. Instead, it creates a “Task Graph.” It decides it needs a Researcher, an Outliner, a Writer, and a Code Reviewer.
09:00:15 - The Researcher (Retrieval)
The Researcher agent (using Gemini 3.5 for its massive context window) starts scouring official documentation, Reddit threads, and GitHub issues. It gathers about 200,000 tokens of raw data.
09:02:00 - The Outliner (Synthesis)
The Outliner takes the raw research and creates a structured skeleton. It realizes that a section on “Pinning” is missing. It sends a message back to the Researcher: “Hey, can you get more info on ‘Pin’ and ‘Unpin’ in Async Rust?”
09:02:30 - The Researcher (Refinement)
The Researcher goes back out, finds the missing info, and updates the shared memory.
09:03:00 - The Writer (Generation)
The Writer agent (using GPT-5.2) starts filling in the outline. It’s working in parallel with the Code Reviewer. As the Writer finishes a code snippet, it “posts” it to the shared hub.
09:03:15 - The Code Reviewer (Verification)
The Code Reviewer picks up the snippet, runs it in a sandboxed environment, catches a subtle borrow-checker error, and sends it back to the Writer: “This won’t compile because of a lifetime issue. Here is the fix.”
09:05:00 - The Lead Editor (Finalization)
The Lead Editor reviews the entire 4,000-word document for tone, flow, and SEO. It adds the internal links and formats the Markdown.
In five minutes, a task that would have taken me 10 hours is done. And because they “argued” over the code and the research, the quality is higher than if I had just asked a single model to “write a post.”
How Do Multi-Agent AI Systems Work?
I often get asked: “How do these agents actually talk to each other?” It’s not magic, and it’s not just a series of API calls. It’s a sophisticated layer of orchestration.
The Core Agent Components
Every agent in a modern MAS usually consists of four “organs”:
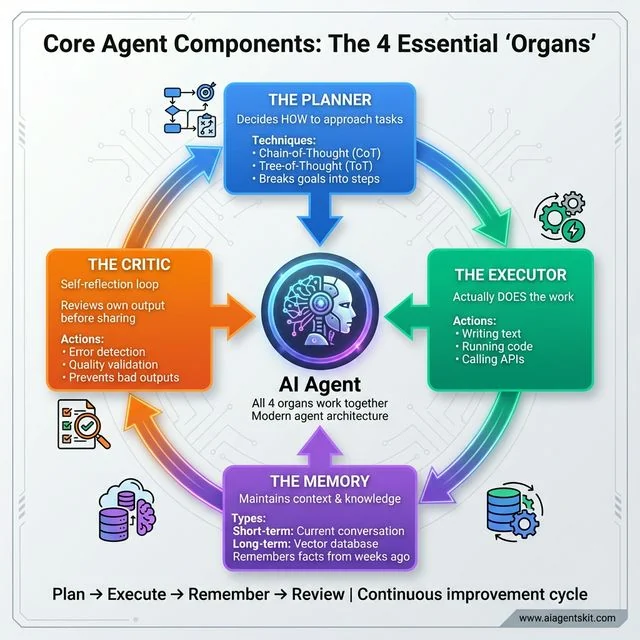 Core Agent Components: Modern AI agents consist of four essential ‘organs’ working in continuous cycle. The Planner uses Chain-of-Thought (CoT) techniques to break goals into executable steps. The Executor performs concrete actions like writing, coding, and API calls. The Memory maintains short-term conversation context and long-term knowledge via vector databases like Pinecone. The Critic provides self-reflection, reviewing outputs before sharing to prevent errors. Together they create the Plan → Execute → Remember → Review cycle that enables autonomous agents capable of complex reasoning and self-correction, far beyond simple chatbots.
Core Agent Components: Modern AI agents consist of four essential ‘organs’ working in continuous cycle. The Planner uses Chain-of-Thought (CoT) techniques to break goals into executable steps. The Executor performs concrete actions like writing, coding, and API calls. The Memory maintains short-term conversation context and long-term knowledge via vector databases like Pinecone. The Critic provides self-reflection, reviewing outputs before sharing to prevent errors. Together they create the Plan → Execute → Remember → Review cycle that enables autonomous agents capable of complex reasoning and self-correction, far beyond simple chatbots.
- The Planner: This is where the agent decides how to approach a task. Using techniques like Chain-of-Thought (CoT) or Tree-of-Thought (ToT), it breaks a big goal into tiny, executable steps.
- The Executor: This is the part that actually “does” the work—writing the text, running the code, or calling an API.
- The Memory (Short-term and Long-term): Short-term memory handles the current conversation context. Long-term memory uses vector databases (like Pinecone or Weaviate) to remember facts from weeks ago.
- The Critic: This is a self-reflection loop. Before sending work to another agent, the agent reviews its own output for errors.
Communication: The “Language” of Agents
For agents to collaborate, they need a protocol. In the early days, we used strict JSON schemas. While those are still used for high-reliability tasks, in 2026, we’ve shifted toward Natural Language as a Protocol (NLaaP).
Agents literally “chat” with each other. A “Manager Agent” might send a message to a “Coder Agent” saying: “I need a Python script to scrape this URL. Please ensure you handle rate limits.” The Coder Agent responds in natural language with the code block.
Why natural language? Because it’s flexible. It allows agents to negotiate, clarify requirements, and even “argue” about the best way to solve a problem—which often leads to better results than a hard-coded logic tree.
Agentic Chaining vs. Agentic Orchestration
This is a nuance that I see trip up even senior engineers. There’s a big difference between Agentic Chaining and Agentic Orchestration.
Agentic Chaining (The Assembly Line)
In a chain, you have a linear sequence. Step A goes to Step B, which goes to Step C. It’s simple, predictable, and works for 40% of use cases. But here’s the problem: if Step B fails, the whole chain often breaks or produces “garbage in, garbage out” results for Step C.
Agentic Orchestration (The Conductor)
Orchestration is non-linear. You have an Orchestrator (the conductor) that evaluates the output of every step. If Step B’s output is low-quality, the Orchestrator doesn’t move to Step C. It sends the task back to Agent B with feedback, or even assigns it to Agent D.
I’ve learned the hard way that for any task involving more than three steps, orchestration is the only way to maintain production-grade reliability. Chaining is for prototypes; orchestration is for products.
Benefits of Multi-Agent AI Architecture
Why bother with all this complexity? Isn’t it just more expensive? I used to think so, but the benefits of multi-agent AI architecture far outweigh the overhead in production environments. According to McKinsey, as of late 2025, over 50% of enterprises are actively utilizing AI agents, with nearly 40% operating more than 10 agents in production environments.
1. Separation of Concerns (The Debugging Lifesaver)
When a single agent fails, it’s hard to know why. Did the prompt fail? Did the model hallucinate? Did the tool return bad data? In a multi-agent system, if the “Researcher” provides bad data, the “Reviewer” will catch it. You can see exactly where the chain broke and fix the specific prompt for that specific agent.
2. Model Heterogeneity (Cost Optimization)
This is a big one for my fellow developers. You don’t need GPT-5.2 to do a simple regex check. In a MAS, you can use:
- Claude 4.5 for high-level reasoning and planning.
- GPT-5.2 for complex coding.
- Llama 4 (Local) for processing sensitive data that shouldn’t leave your server.
- Gemini 3.5 for high-speed, long-context data retrieval.
By matching the model to the task, I’ve seen teams reduce their token costs by up to 60% while actually improving performance.
3. Parallelization and Speed
Single agents are sequential—they do Step A, then Step B, then Step C. In a MAS, your “Research Agent” can start looking for Competitor 2 while your “Writer Agent” is already drafting the summary for Competitor 1. It’s the difference between a one-man shop and a factory line.
4. Distributed Resilience
If one agent hits a rate limit or experiences a temporary failure, the whole system doesn’t have to crash. The orchestrator can retry that specific task or even spin up a “Backup Agent” from a different provider.
AI Agent Swarms vs. Orchestrated Teams
Here’s a distinction that often confuses people: the difference between a “Crew” (like in CrewAI) and a “Swarm” (like OpenAI Swarm).
The Orchestrated Team (The “Crew”)
This is a top-down approach. You have a defined hierarchy. There is usually a Supervisor Agent that delegates tasks to specialized workers. It’s very predictable and great for business processes like “Generate Monthly SEO Report.”
The AI Agent Swarm (The “Hive”)
An AI agent swarm is more decentralized. It’s inspired by nature (think ants or bees). You have hundreds of simple agents that communicate laterally. There is no “boss.” Instead, they follow simple rules that lead to complex emergent behavior.
I’ve seen swarms used for massive data-crawling projects where the system needs to self-organize to cover millions of pages without a central coordinator bottlenecking the process. If you’re building for scale, understanding swarms is critical.
Technical Deep Dive: The Orchestrator’s Logic
Let’s talk about the “brain” of the system: the Orchestrator. When things go wrong (and they will), how does the Orchestrator handle it? In my experience, a robust orchestrator needs three levels of error handling:
- Level 1: The Retry (Self-Correction): If an agent returns an error or malformed JSON, the Orchestrator sends the error back to the same agent with a “Retry” command. “You missed a comma in your output, please fix it.”
- Level 2: The Fallback (Model Switching): If the agent fails three times, the Orchestrator switches the model. If GPT-5.2 keeps failing at a complex logic task, it might spin up a Claude 4.5 agent to try the same task from a different perspective.
- Level 3: The Human Intervention: If both models fail, the Orchestrator doesn’t just crash. It flags the “State,” saves the progress, and sends a notification to me. I can see exactly where they got stuck, give them a hint in the chat, and let them continue.
This “graceful degradation” is why multi-agent systems are finally ready for production.
Agent-to-Agent Negotiation Protocols
Here’s something I’ve been experimenting with: Agent Negotiation. In complex systems, agents don’t just follow orders; they negotiate for resources.
Imagine a system with a limited “Token Budget.” The “Research Agent” might want 100,000 tokens for a deep dive, but the “Summarizer Agent” only has 10,000 tokens left in the budget. They actually “discuss” the trade-offs.
- Research Agent: “I need 100k tokens to ensure accuracy on the medical data.”
- Budget Agent: “We only have 50k left for this session. Can you prioritize the last 2 years of research?”
- Research Agent: “Accepted. I will filter for 2024-2026 sources only.”
This kind of interaction—often implemented using Contract Net Protocols—is what makes 2026-era systems feel truly autonomous. They are solving their own resource constraints instead of just crashing.
State Management and Memory in 2026
When you move from one agent to five, you suddenly have a “State” problem. Who knows what? If Agent A finds a piece of information, does Agent E know it?
In 2026, we’ve moved past simple “Chat History.” We now use three layers of memory:
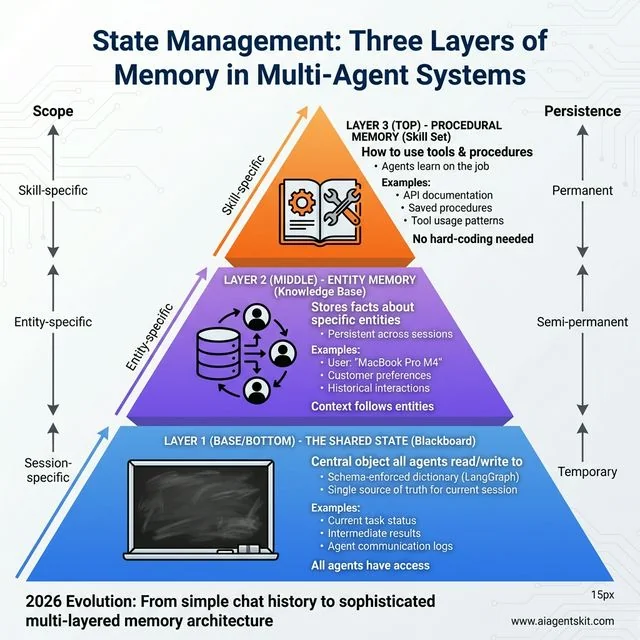 State Management: Three Layers of Memory in Multi-Agent Systems. The 2026 evolution solves the “who knows what” problem through layered architecture. Layer 1 - Shared State (blue, base) provides session-specific temporary storage for task status and agent communication, implemented as schema-enforced dictionaries in LangGraph. Layer 2 - Entity Memory (purple, middle) stores semi-permanent facts about entities like user preferences (“MacBook Pro M4”) that persist across sessions. Layer 3 - Procedural Memory (orange, top) enables agents to learn new tools by reading documentation and saving procedures—they can “study” on the job rather than requiring hard-coded integrations. This pyramid progresses from broad temporary data to focused permanent skills.
State Management: Three Layers of Memory in Multi-Agent Systems. The 2026 evolution solves the “who knows what” problem through layered architecture. Layer 1 - Shared State (blue, base) provides session-specific temporary storage for task status and agent communication, implemented as schema-enforced dictionaries in LangGraph. Layer 2 - Entity Memory (purple, middle) stores semi-permanent facts about entities like user preferences (“MacBook Pro M4”) that persist across sessions. Layer 3 - Procedural Memory (orange, top) enables agents to learn new tools by reading documentation and saving procedures—they can “study” on the job rather than requiring hard-coded integrations. This pyramid progresses from broad temporary data to focused permanent skills.
1. The Shared State (The “Blackboard”)
This is a central object that all agents can read from and write to. In frameworks like LangGraph, this is often implemented as a schema-enforced dictionary. It’s the “single source of truth” for the current session.
2. Entity Memory (The “Knowledge Base”)
This is where the system stores facts about specific entities. If your “Customer Support Team” learns that a user is using a “MacBook Pro M4,” that fact is stored in an Entity Memory. Any agent that interacts with that user in the future will automatically have that context.
3. Procedural Memory (The “Skill Set”)
This is my favorite development of the last year. Agents can now “learn” how to use a new tool by reading its documentation and then saving that procedure into their Procedural Memory. This means you don’t have to hard-code every tool into every agent. They can “study” on the job.
For Claude users looking to customize individual agents with persistent configurations, Claude Agent Skills provide a filesystem-based approach to reusable agent expertise.
Agentic RAG: The Next Level of Retrieval
Standard RAG (Retrieval-Augmented Generation) is dead. Or at least, it’s a commodity. In 2026, the pros use Agentic RAG. As experts at Pinecone have noted, the shift to agentic systems allows LLMs to act as reasoning engines that can autonomously plan and execute multi-step retrieval tasks.
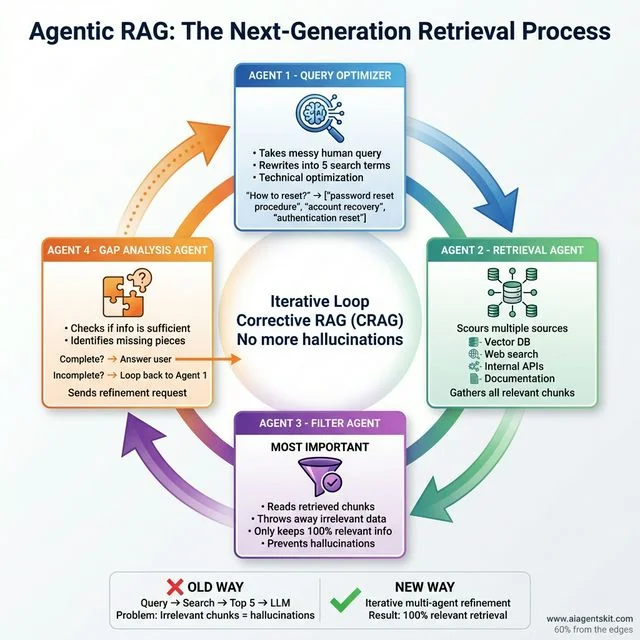 Agentic RAG: Four specialized agents solve traditional RAG’s hallucination problem through Corrective RAG (CRAG). Query Optimizer rewrites messy queries into precise search terms. Retrieval Agent scours Vector DB, web, and APIs for potentially relevant chunks. Filter Agent (most critical) discards anything not 100% relevant to prevent hallucinations. Gap Analysis Agent checks completeness—if sufficient, answers user; if incomplete, loops back with refinement requests. This iterative approach beats the old “Query → Top 5 → LLM” method where irrelevant chunks caused hallucinations. Result: 100% relevant retrieval that makes AI systems truly “understand” your documentation.
Agentic RAG: Four specialized agents solve traditional RAG’s hallucination problem through Corrective RAG (CRAG). Query Optimizer rewrites messy queries into precise search terms. Retrieval Agent scours Vector DB, web, and APIs for potentially relevant chunks. Filter Agent (most critical) discards anything not 100% relevant to prevent hallucinations. Gap Analysis Agent checks completeness—if sufficient, answers user; if incomplete, loops back with refinement requests. This iterative approach beats the old “Query → Top 5 → LLM” method where irrelevant chunks caused hallucinations. Result: 100% relevant retrieval that makes AI systems truly “understand” your documentation.
The old way was: User Query → Embeddings Search → Top 5 Chunks → LLM Summary. The problem? If the Top 5 chunks are irrelevant, the LLM hallucinates.
Agentic RAG fixes this by turning the retrieval process into a multi-agent workflow:
- The Query Optimizer Agent: Takes your messy human query and rewrites it into five different technical search terms.
- The Retrieval Agent: Scours multiple sources (Vector DB, Web, API).
- The Filter Agent: This is the most important part. It reads the retrieved chunks and throws away anything that isn’t 100% relevant.
- The Gap Analysis Agent: If the remaining info isn’t enough to answer the question, it sends a command back to the Optimizer: “Hey, we need more info on specifically X.”
This iterative loop—often called Corrective RAG (CRAG)—is why modern AI systems finally feel like they actually “understand” your internal documentation.
Multi-Modal Multi-Agent Systems
If you think agents are just for text, you’re living in 2024. Today, we have Multi-Modal Multi-Agent Systems.
I recently built a “Video Content Auditor” for a media company. It uses three specialized agents:
- The Vision Agent: Scans the video frames for brand logos, faces, and “unsafe” content.
- The Audio Agent: Transcribes the dialogue but also analyzes the tone and emotion of the speakers.
- The Compliance Agent: Takes the output from both and checks it against the company’s 200-page brand safety manual.
Because these agents can “see” and “hear” simultaneously, they catch nuances that a single model would miss. For example, the Vision Agent might see a person smiling, but the Audio Agent hears sarcasm. The Compliance Agent then flags this as a potential brand risk. This cross-modal collaboration is where the real power of MAS lies.
Multi-Agent Reinforcement Learning (MARL) Explained Simply
If you want to get into the high-end side of MAS, you’ll eventually run into Multi-Agent Reinforcement Learning (MARL). Don’t let the name intimidate you; it’s actually a very intuitive concept.
In standard Reinforcement Learning (RL), one agent learns by trial and error to maximize a “reward.” In MARL, multiple agents are learning at the same time in the same environment.
The Soccer Analogy
Think of MARL like training a soccer team.
- If you only train the striker, they might score a lot, but the team will lose because they don’t have a goalie.
- In MARL, the agents (players) learn that their individual success depends on the collective success.
- The goalie learns that keeping the ball out of the net is just as valuable as the striker putting it in.
In 2026, MARL is being used to optimize things like global supply chains and traffic management systems where thousands of “agents” (trucks, ships, traffic lights) need to learn how to cooperate to prevent gridlock. For a deeper technical dive into these concepts, the Stanford AI Lab provides extensive resources on multi-agent cooperation and competition.
Multi-Agent Architecture Patterns
How do you actually structure these systems? I’ve experimented with dozens of patterns, but these four are the “Big Four” you’ll use 90% of the time.
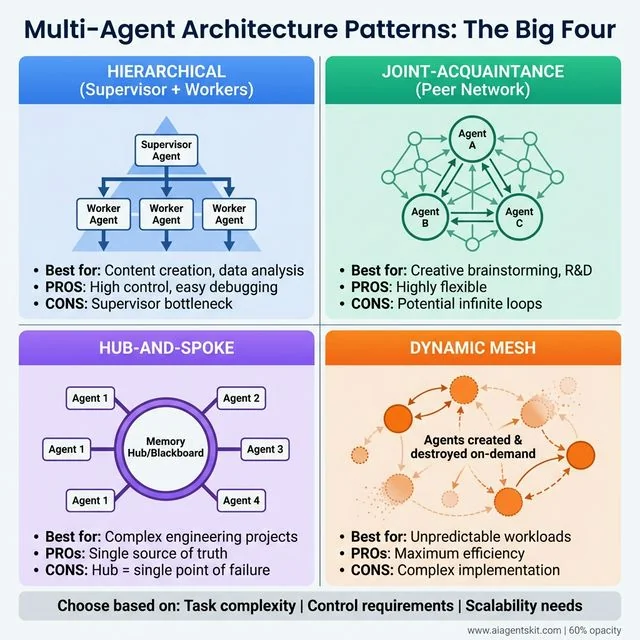 Multi-Agent Architecture Patterns: The Big Four covering 90% of 2026 use cases. HIERARCHICAL (blue): Supervisor delegates to workers—high control, easy debugging, but supervisor can bottleneck. Best for content creation. JOINT-ACQUAINTANCE (green): Peer-to-peer network without hierarchy—highly flexible for R&D, but risk of infinite loops. HUB-AND-SPOKE (purple): Central memory hub with agents connecting radially—single source of truth for engineering projects, but hub is single point of failure. DYNAMIC MESH (orange): Agents created/destroyed on-demand—maximum efficiency for unpredictable workloads, but complex to implement. Choose based on task complexity, control requirements, and scalability needs.
Multi-Agent Architecture Patterns: The Big Four covering 90% of 2026 use cases. HIERARCHICAL (blue): Supervisor delegates to workers—high control, easy debugging, but supervisor can bottleneck. Best for content creation. JOINT-ACQUAINTANCE (green): Peer-to-peer network without hierarchy—highly flexible for R&D, but risk of infinite loops. HUB-AND-SPOKE (purple): Central memory hub with agents connecting radially—single source of truth for engineering projects, but hub is single point of failure. DYNAMIC MESH (orange): Agents created/destroyed on-demand—maximum efficiency for unpredictable workloads, but complex to implement. Choose based on task complexity, control requirements, and scalability needs.
1. Hierarchical (Supervisor + Workers)
This is the most common pattern. A supervisor agent takes the user input, creates a plan, and assigns tasks to workers.
- Best for: Content creation, data analysis, and customer support.
- Pros: High control, easy to debug.
- Cons: The supervisor can become a bottleneck.
2. Joint-Acquaintance (The Peer Network)
There is no supervisor. Agents are “peers” who know about each other’s capabilities. When an agent receives a task it can’t handle, it “asks around” to see if anyone else can help.
- Best for: Creative brainstorming or R&D.
- Pros: Highly flexible.
- Cons: Can lead to “infinite loops” if agents keep passing the buck.
3. Hub-and-Spoke
A central “Memory Hub” or “Blackboard” exists where all agents post their findings. Agents don’t talk to each other directly; they just read and write to the hub.
- Best for: Complex engineering projects.
- Pros: Excellent for maintaining a “single source of truth.”
- Cons: The hub can become a single point of failure.
4. Dynamic Mesh
In this 2026-era pattern, agents are created and destroyed on the fly. If the system realizes it needs a “Legal Expert,” it dynamically spins up an agent with that specific persona and toolset, uses it, and then deletes it to save costs.
- Best for: High-complexity, unpredictable workloads.
- Pros: Maximum efficiency.
- Cons: Extremely complex to implement.
Human-in-the-loop (HITL) Patterns
One of the biggest mistakes I see people make is trying to build a 100% autonomous system. In 2026, the most successful multi-agent systems are “Human-augmented.” We call this Human-in-the-loop (HITL).
The “Interrupt-and-Approve” Pattern
The agents work until they reach a high-stakes decision (like spending money or deleting data). The system then pauses and sends a notification to the human. The human can see the “State” of the system, read the internal “chat” between the agents, and click “Approve” or “Reject.”
The “Suggest-and-Execute” Pattern
The agents provide three options to the human. The human picks one, and the agents then execute the entire downstream workflow based on that choice.
I’ve found that adding just one human approval step increases the reliability of a system from 85% to 99.9%. Don’t be afraid to keep the human in the driver’s seat.
Real-World Multi-Agent System Examples
Let’s move away from the theory. Here is how I’m seeing these systems deployed in the real world right now.
Software Development: Self-Healing Systems
We’ve moved beyond Devin. In 2026, the hottest trend in DevOps is Autonomous Self-Healing.
- The Monitor Agent: Watches production logs 24/7.
- The Diagnostician Agent: When a 500 error spikes, it traces the stack trace to the specific commit.
- The Fixer Agent: Spins up a feature branch, writes a fix, and passes it to the QA agent.
- The QA Agent: Runs the full regression suite. If it passes, it pings the human SRE for a one-click deployment.
- I’ve seen companies reduce their Mean Time To Recovery (MTTR) from hours to under 4 minutes using this pattern.
Healthcare: The “Diagnostic Board”
In modern clinics, MAS are helping doctors avoid burnout:
- Agent 1 (Radiology Specialist): Analyzes the MRI scans.
- Agent 2 (Geneticist Specialist): Reviews the patient’s DNA markers.
- Agent 3 (Pharmacist Specialist): Checks for drug interactions based on the patient’s current meds.
- Agent 4 (General Practitioner): Synthesizes these reports into a clear summary for the human doctor.
- This isn’t replacing doctors; it’s giving them a board of advisors that works at the speed of light.
Marketing: The “Content Factory”
Many of the blog posts you read today are generated by agent crews:
- Trend Agent: Scours Twitter/X and Reddit for trending topics.
- Fact-Checker Agent: Verifies claims against authoritative sources like Wikipedia or official docs.
- SEO Agent: Optimizes headings and metadata.
- Image Agent: Creates the featured image using DALL-E 4 or Midjourney.
For more inspiration on where these agents are making an impact, see our AI agent use cases.
Legacy System Integration: The “Wrapper” Agent
One of the biggest hurdles I faced in 2025 was getting these fancy agents to talk to “Legacy” systems—old SQL databases, SAP instances, or even proprietary COBOL mainframes.
The solution? The Wrapper Agent. Instead of trying to make your “Orchestrator” understand COBOL, you create a specialized agent whose only job is to be the interface for that system. It speaks “Agent-Speak” (NLaaP) on one side and “Legacy-Speak” on the other.
I’ve used this to give a modern AI frontend to a 30-year-old inventory management system. The agents “think” they are just talking to another teammate, while the Wrapper Agent is busy writing SQL queries and parsing CSV files in the background. This is how you bring AI to the enterprise without rebuilding everything from scratch.
Challenges and Limitations (The “Real Talk”)
I wouldn’t be doing my job if I didn’t warn you: MAS is not a silver bullet. It comes with its own set of headaches.
1. Agent Drift (The Telephone Game)
This is a weird one. Sometimes, when agents talk to each other for too long, they start to “drift” away from the original goal. It’s like a game of telephone. The Researcher says one thing, the Writer misinterprets it, and by the time it gets to the Editor, the original fact is gone.
Pro-tip: I always add a “Grounding Agent” whose only job is to compare the final output against the initial user request and the original research. If it finds a discrepancy, it sends the whole thing back for a “Reset.”
2. The Cost of Communication
Every time an agent sends a message to another agent, you’re paying for tokens. In a complex 5-agent system, a single user query can easily trigger 50+ LLM calls. If you aren’t careful, your API bill will look like a mortgage payment.
I’ve seen “chatty” agents get into loops where they apologize to each other for 10 messages straight, burning $5.00 in tokens for no reason. You need “Muzzle” logic to prevent unnecessary politeness between bots.
3. Latency
Multiple agents working together takes time. Even with parallelization, the “reasoning time” adds up. If your user expects an answer in under 2 seconds, a multi-agent system might not be the right choice. MAS is better for “async” work—things that happen in the background.
4. Security Risks (The “Social Engineering” of Agents)
In a MAS, one compromised agent can “trick” another. If a “Researcher” is tricked by a malicious website into thinking the user wants to delete their database, it might send a command to the “Database Agent” that looks legitimate. Securing agent-to-agent communication is the new frontier of AI safety. We are now using “Internal Firewalls” between agents to prevent this kind of horizontal movement.
Privacy-Preserving Agent Architectures
As we give agents more power, we give them more data. In 2026, Privacy-Preserving Agent Architectures are no longer optional—they are a legal requirement in many regions.
The pattern I recommend is the Local-Cloud Split:
- The Privacy Agent (Local): Runs a small model (like Phi-4 or Llama-4-8B) on your local hardware. It “scrubs” all PII (Personally Identifiable Information) from the data.
- The Reasoning Agents (Cloud): Receive the anonymized data and perform the heavy lifting.
- The Re-Identification Agent (Local): Receives the cloud output and re-inserts the private details before showing it to the human.
This way, your sensitive data never leaves your premises, but you still get the “IQ” of the massive cloud models. If you’re building for Enterprise, this is the architecture you need to pitch.
Benchmarking and “Agentic” ROI
“How do I know if my multi-agent system is actually better than a single agent?”
In 2024, we looked at “Accuracy.” In 2026, that’s not enough. We now use three core metrics:
- Task Completion Rate (TCR): How often does the system actually reach the “Goal State”?
- Cost-per-Success (CPS): Total token cost divided by successful outcomes. (This is a better metric than cost-per-1k tokens).
- Agentbench 3.0 Score: A standardized benchmark that tests how well agents use tools and follow complex instructions.
I once spent three weeks optimizing a system that had 95% accuracy but a CPS of $12.00 per task. By moving the “Reviewer” to a cheaper model and improving the Orchestrator’s retry logic, I got the CPS down to $0.45 without losing a single percentage point of accuracy. That’s the kind of ROI that gets projects funded.
Frameworks for Building Multi-Agent Systems
You don’t need to write the orchestration logic from scratch. In 2026, we have some incredible tools that handle the “plumbing” for us.
LangGraph (The Power User’s Choice)
From the LangChain team, LangGraph is built for “stateful” agents.
- Key Feature: It treats your agent workflow as a “Graph.” This allows for cycles (looping back to fix an error) which is something basic LangChain struggled with.
- When to use: When you need absolute control over the flow and state management.
AutoGen (The Conversation King)
Microsoft’s AutoGen is all about “Conversable Agents.”
- Key Feature: It makes it incredibly easy to let agents talk to each other with minimal code. It also has great support for “Human-in-the-loop” (HITL) where a human can step in and provide feedback mid-conversation.
- When to use: For complex simulations and interactive problem-solving.
CrewAI (The Role-Based Favorite)
CrewAI is what I recommend for 90% of business use cases.
- Key Feature: It focuses on “Roles.” You define a Researcher, a Writer, and a Manager. You give them “Tasks.” The framework handles the rest.
- When to use: When you want to get up and running quickly with a reliable, hierarchical team.
OpenAI Swarm (The Minimalist Approach)
OpenAI recently released Swarm as an experimental, lightweight framework.
- Key Feature: It’s “stateless” and focuses on handoffs. It’s incredibly fast and easy to understand.
- When to use: For simple multi-agent setups where you just need clean agent-to-agent transitions.
For a deeper dive into your options, see our best AI agent frameworks comparison.
The Future of Multi-Agent Systems (2027 and Beyond)
I’m often asked where this is all going. If 2026 is the year of the “Agent Crew,” 2027 will be the year of the Inter-agent Economy.
We’re already seeing early versions of this: agents that have their own crypto wallets and pay other agents for services. Imagine your “Writer Agent” needs a high-quality illustration. Instead of asking you, it goes to an “Illustration Marketplace,” finds an agent that specializes in your brand’s style, negotiates a price (in micro-tokens), and pays for the work autonomously.
We’re moving toward a web where the majority of traffic isn’t human-to-human, but agent-to-agent. This is why understanding distributed AI systems is no longer optional for anyone in tech—it’s the new foundation of the digital economy. According to Deloitte, 25% of enterprises using generative AI will have fully deployed AI agents by the end of 2025, paving the way for this autonomous future.
When to Use Multi-Agent Architecture (The Decision Matrix)
Still not sure if you need a team or a solo agent? Use this checklist:
Go Multi-Agent if:
- The task has distinct phases (e.g., Research → Write → Code → Test).
- You need to use different models for different steps to save money.
- The task is too large for a single context window (e.g., analyzing a 500-page PDF).
- You need high reliability through “double-checking” (Reviewer agents).
Stick to a Single Agent if:
- It’s a simple Q&A task.
- You need sub-second latency.
- You’re on a very tight budget.
- You’re just starting out and want to keep things simple.
Ready to start building? Check out our tutorial on how to build your first AI agent as a foundation before you try to scale to a full system.
Frequently Asked Questions
What is a multi-agent system in AI?
A multi-agent system (MAS) is an architecture where multiple AI agents work together to solve complex problems. Each agent has its own role, tools, and memory, and they communicate to achieve a shared goal, much like a team of human specialists.
Why use multiple AI agents instead of one?
Multiple agents allow for better specialization, reduced “hallucinations,” and lower costs through heterogeneous model usage. They also enable parallel processing and better handling of large context windows.
What is an AI agent swarm?
An AI agent swarm is a decentralized group of agents that cooperate without a central supervisor. It’s inspired by biological systems and is ideal for large-scale, distributed tasks like data crawling or system monitoring.
How do multi-agent AI systems work?
They work through an orchestration layer that manages communication (usually via natural language or JSON), task delegation, and state management. Agents use planners to break down goals and executors to take actions.
Is multi-agent reinforcement learning (MARL) hard to learn?
The concept is simple: multiple agents learning to cooperate in the same environment. However, the math and implementation can be complex. In 2026, most developers use high-level frameworks like Ray or RLlib to handle the heavy lifting.
What is the best framework for multi-agent systems in 2026?
It depends on your needs. LangGraph is best for complex, stateful workflows; CrewAI is best for business process automation; and AutoGen is ideal for conversational AI and simulations.
How do agents handle conflicting information?
Agents typically use a “Consensus” or “Debate” protocol. A Reviewer agent or Supervisor agent compares the conflicting data, looks at the sources, and makes a final determination. In some systems, they might even “vote” on the most likely correct answer.
Can I build a multi-agent system with only one LLM provider?
Yes, but you lose the “Model Heterogeneity” benefit. Many systems use only OpenAI or only Anthropic, but the most resilient ones mix providers to avoid being affected by a single provider’s outage or model updates.
What is the “Microservices Moment” for AI?
It refers to the shift from building massive, all-in-one “Monolithic” agents to building small, specialized, orchestrated “Micro-agents.” This allows for easier scaling, debugging, and maintenance, just like the shift from monoliths to microservices in traditional software.
How do multi-agent systems ensure security?
In 2026, we use “Agent Firewalls” and strict capability-based access control. We also use a “Watchdog Agent” to monitor the internal chat for signs of manipulation or unauthorized commands.
What is the ROI of moving to a multi-agent system?
While development cost is higher, the ROI comes from significantly higher task completion rates and lower long-term operational costs by using smaller models for sub-tasks. I’ve seen success rates jump from 60% to 98% after moving from a single agent to a multi-agent crew.
The Future of Collaboration
I honestly believe we are moving toward a world where every professional has their own “Squad” of AI agents. You won’t just “use AI”—you’ll “manage a team of AIs.”
The shift from monolithic models to multi-agent systems is the most exciting architectural change I’ve seen in my career. It’s moving us from “AI as a tool” to “AI as a teammate.”
Start small. Build one agent that does one thing perfectly. Then, build a second agent that reviews the first one. Before you know it, you’ll have a world-class team working for you 24/7. And if you’re looking for a practical industry example, check out our deep dive on real estate AI agents to see how these teams are being deployed in the field.