Agentic AI Frameworks: The Complete Guide (2026)
Compare top agentic AI frameworks in 2026 with a head-to-head matrix. Real-world examples from LinkedIn, Genentech & more. LangChain, CrewAI, AutoGen, LangGraph, Google ADK compared side by side.
By the end of 2026, Gartner projects that 40% of enterprise applications will incorporate task-specific AI agents — up from less than 5% in 2025. That’s not a gradual adoption curve; it’s a structural shift in how software gets built.
The problem most developers and tech leads face isn’t a shortage of options — it’s an overwhelming number of frameworks claiming to solve agentic AI, each with different philosophies, tradeoffs, and production readiness levels. Picking the wrong one early means refactoring expensive pipelines six months later.
This guide covers what agentic AI frameworks do, breaks down the seven most widely used options as of 2026, and provides a practical decision framework for choosing the right one based on your use case, team size, and infrastructure — so those reading this can move from evaluation to deployment faster.
What Is an Agentic AI Framework?
An agentic AI framework is a software toolkit that enables autonomous AI systems to plan, reason, and take multi-step actions to achieve goals — without requiring explicit human instruction at every step. Understanding what AI agents are is the foundation, but a framework is what turns that concept into a deployable system.
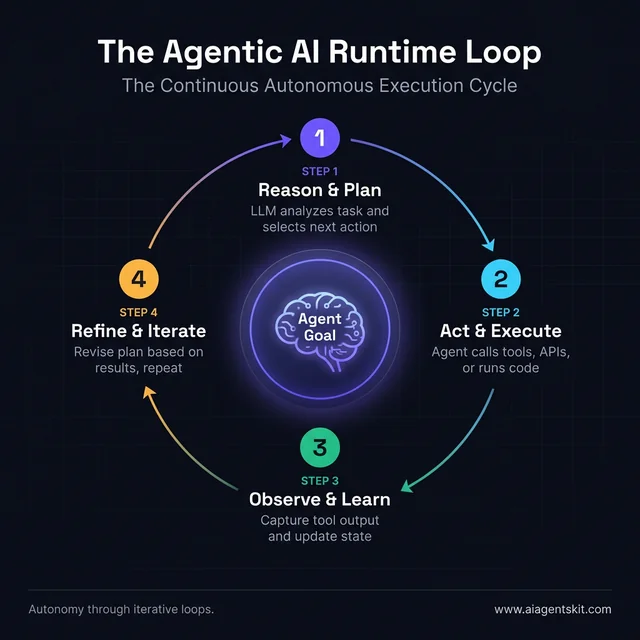
The distinction matters deeply. Traditional AI models respond to prompts and return outputs in a single pass. Agentic systems go further: they can use tools (web search, code execution, APIs), maintain memory across interactions, hand off tasks to other agents, and revise their approach based on intermediate results. The agent observes what happened, reasons about what to do next, and acts — repeating the loop until the goal is met or a threshold is hit.
A framework provides the scaffolding that makes this possible. That includes abstractions for tool integration, state management, multi-agent orchestration, and the logic that connects the LLM’s reasoning to real-world actions. Without a framework, teams spend weeks building infrastructure that already exists — usually with worse reliability and more technical debt to maintain going forward.
The practical difference becomes visible fast. A developer building an agent from scratch needs to handle: prompt construction for tool selection, parsing tool outputs, retry logic on failures, managing conversation history within context limits, logging for observability, and coordinating across multiple agents if the task warrants it. A framework handles most of this. The developer focuses on the task logic and the tools — not the plumbing.
According to McKinsey’s 2025 research on agentic AI in the workplace, 23% of companies were already scaling an agentic AI system in at least one business function, with an additional 39% actively experimenting. That widespread adoption reflects how mature the frameworks have become — production deployment is now viable for teams without deep AI research backgrounds, which wasn’t true two years ago.
Agentic frameworks differ from generative AI tools in a fundamental way: they’re designed for loops, not one-shot completions. An agent using a framework can search the web, summarize findings, identify gaps, search again with refined queries, and present a structured conclusion — all as a single execution flow. The framework manages that entire loop, including error handling when any step returns unexpected results.
5 Core Components Every Agentic AI Framework Needs
Not all agentic AI frameworks are built equal. When evaluating any option, five core capabilities determine whether a framework can handle real production workloads.
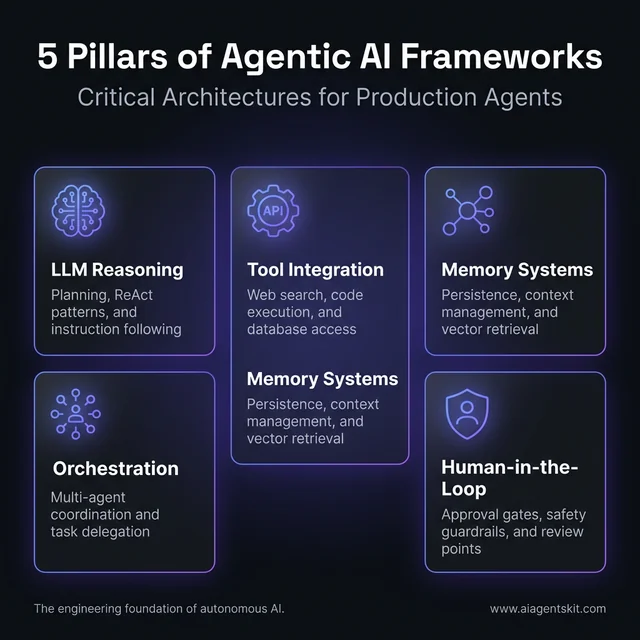
LLM Reasoning & Planning Engine
The foundation of every agentic system is how the underlying language model reasons about tasks and plans steps to complete them. Most frameworks implement a variant of the ReAct pattern — Reason, Act, Observe — where the LLM alternates between thinking through what to do and executing tool calls.
Model choice matters here. Claude 4 Opus tends to excel at multi-step reasoning and instruction-following in long agentic chains. GPT-5 offers strong general performance with broad API ecosystem integration. Gemini 3 Pro’s 2M-token context window makes it uniquely suited for agents that must hold large knowledge bases in context. The framework should support swapping models without major architecture changes.
Tool Use and External Integrations
Agents become genuinely useful when they can interact with the external world — running code, querying databases, calling APIs, browsing the web, or writing to files. A framework’s value is partly measured by the breadth and reliability of its tool integrations.
LangChain’s 700+ pre-built integrations set the benchmark here. Smaller frameworks trade depth for simplicity — a tradeoff that’s reasonable for narrow use cases but becomes a bottleneck as workflows grow in complexity. Teams should map their required integrations before selecting a framework, not after.
Agent Memory: Short-Term and Long-Term
Memory is one of the most underestimated components of agent memory systems. Short-term memory refers to context management within a single session — how the agent tracks what it’s already done, what it’s learned, and what comes next. Long-term memory involves persisting information across sessions, typically via vector databases, key-value stores, or structured knowledge graphs.
Frameworks that handle LangChain agents with persistent state — like LangGraph’s checkpointing system — give teams the ability to build agents that improve over time and resume interrupted workflows without starting from scratch. For enterprise deployments, this isn’t optional.
Orchestration and Multi-Agent Coordination
Complex tasks often exceed what a single agent can reliably accomplish. Multi-agent orchestration — where specialized agents collaborate to solve different parts of a problem — is the architecture that makes ambitious workflows tractable.
Different frameworks take different approaches: hierarchical (a manager agent delegates to workers), sequential (agents hand off results in order), or graph-based (agents operate as nodes in a workflow graph with conditional routing). The right model depends on task structure. Pipeline-style tasks suit sequential approaches; dynamic, branching workflows typically need graph-based orchestration.
Human-in-the-Loop Controls
Production agentic systems can’t operate without approval gates and intervention points. Whether it’s flagging a high-risk action for human review, pausing before executing an irreversible operation, or providing audit trails for compliance, human-in-the-loop controls separate experimental demos from enterprise deployments.
Frameworks that treat this as an afterthought create governance headaches later. The best options — including LangGraph and AutoGen — build these controls into the orchestration layer, making them configurable rather than bolted on.
The 7 Best Agentic AI Frameworks Compared in 2026
Framework selection is an architectural decision, not a software preference. The right choice depends on workflow complexity, team expertise, existing infrastructure, and production requirements. Understanding multi-agent systems helps clarify which framework architecture best fits a given problem.
According to Gartner’s 2025 strategic technology report, agentic AI represents one of the defining shifts for enterprise software in 2026 — which is why framework selection decisions made now will shape platform architecture for the next several years.
LangChain and LangGraph: Production-Grade Control
LangChain remains the most widely adopted framework for LLM-powered applications, and for good reason: it offers the largest ecosystem of integrations (700+), a modular architecture that allows teams to compose complex pipelines, and an active community producing regular updates.
LangGraph, LangChain’s graph-based extension, is the production-focused layer. It models agent workflows as directed graphs — nodes represent actions or decisions, edges represent the flow between them. This enables branching logic, conditional routing, and non-linear workflows that simpler sequential frameworks can’t handle. Companies like LinkedIn, Uber, and Replit use LangGraph in production, citing its reliability, built-in error recovery, and state persistence through checkpointing.
In 2026, the LangSmith Agent Builder reached general availability, allowing teams to create agents using natural language and monitor them through an observability dashboard. LangChain 1.x entered long-term support through December 2026.
Best for: Complex, stateful, production-grade pipelines; teams that need fine-grained control over every step; workflows with conditional logic or long-running tasks.
CrewAI: Role-Based Multi-Agent Collaboration
CrewAI takes a different philosophical approach: it frames multi-agent collaboration as a team of specialists — a “crew” — where each agent has a defined role, goal, and backstory. The mental model aligns closely with how human teams divide work, which makes it surprisingly intuitive to reason about.
The framework supports sequential pipelines (one agent to the next) and hierarchical structures (a manager agent that orchestrates workers). CrewAI’s process definitions make role boundaries explicit, preventing the “everything becomes everyone’s problem” failure mode common in loosely orchestrated multi-agent systems.
For enterprise adoption, CrewAI’s AMP (Agent Management Platform) provides centralized monitoring, security controls, and serverless scaling — features that matter once agents move from proof-of-concept into production environments with real traffic.
Best for: Content creation pipelines, research workflows, structured business processes where roles can be clearly defined; teams building multi-agent systems for the first time.
Microsoft AutoGen: Conversational Multi-Agent AI
AutoGen treats agent collaboration as a conversation — agents communicate with each other in structured dialogue to reason through problems collaboratively. This approach excels at tasks that benefit from critique and iteration: research synthesis, code review, evaluation pipelines, and exploratory analysis.
The 2026 AutoGen v2 redesign introduced an asynchronous, event-driven architecture for better scalability and observability. AutoGen’s core framework has merged with Microsoft’s Semantic Kernel within Azure AI Foundry, creating a unified enterprise stack for Azure-centric organizations. AutoGen v1 was deprecated in January 2026.
The conversation-driven model does introduce overhead. “Consensus-building” between agents can be slower than explicit state machines. For tasks where execution speed matters more than iterative refinement, AutoGen may not be the right fit.
Best for: Microsoft/Azure environments; collaborative reasoning tasks; research, data analysis, and evaluation workflows; teams that value dialogue-based agent coordination.
Google Agent Development Kit (ADK)
Google’s Agent Development Kit is optimized for Gemini 3 model family and enterprise deployments on Google Cloud. It provides built-in tooling specifically tuned for Gemini’s capabilities, including the model’s 2M-token context window for Pro and deep Vertex AI integration for scalable, managed deployments.
ADK is a relatively newer entrant compared to LangChain or AutoGen, which means its ecosystem is smaller — but for teams already building on GCP and using Gemini models, the native integration advantages are significant. The abstraction layer is thinner, meaning less framework-specific overhead for Gemini-native workflows.
Best for: Teams with GCP infrastructure and Gemini-first deployment strategies; organizations wanting native SDK support rather than adapter-based integration.
OpenAI Assistants API and Frontier Platform
OpenAI’s Assistants API provides managed infrastructure for agent deployment — handling thread management, tool execution, and persistent context, with built-in support for file retrieval, code execution, and function calling. It abstracts away much of the orchestration plumbing, enabling rapid agent deployment for teams that don’t need full framework control.
The Frontier platform, aimed at enterprise-scale deployments, is designed to help large organizations deploy agents across existing systems and business workflows. OpenAI has partnered with McKinsey, BCG, Accenture, and other major consulting firms through “Frontier Alliances” to accelerate enterprise adoption.
Best for: Teams who are already deep in the OpenAI API ecosystem; rapid initial deployment; organizations working with OpenAI’s enterprise integration programs.
Semantic Kernel: Microsoft’s Enterprise SDK
Semantic Kernel is a lightweight, language-agnostic SDK designed to integrate AI capabilities into existing applications — particularly in .NET and C# environments — without requiring teams to rebuild their application architectures. It bridges existing enterprise software and modern LLM capabilities through a plugin-based design.
In 2026, Semantic Kernel’s capabilities merged with AutoGen within Azure AI Foundry, creating a unified framework for enterprise AI development on Azure. This convergence positions it as the preferred path for Microsoft-stack teams who need both agent orchestration and application integration.
Best for: Enterprises with existing .NET applications; Azure-native development teams; scenarios where AI needs to be added to established applications rather than built from scratch.
LlamaIndex: Data-Centric Agent Framework
LlamaIndex is purpose-built for agents that need to reason over large volumes of proprietary enterprise data. While other frameworks focus on orchestration and tool use, LlamaIndex specializes in data ingestion, indexing, and retrieval — making it the best-in-class option for knowledge-intensive agent applications.
Its strengths come through in RAG architectures, document QA systems, and internal knowledge bases where the quality of information retrieval directly determines agent accuracy. LlamaIndex integrates with most vector databases and LLMs, and it sits comfortably alongside other frameworks rather than replacing them.
Best for: Knowledge-intensive applications; RAG systems; internal document assistants; scenarios where agent accuracy depends heavily on retrieval quality over external tool use.
Agentic AI Framework Comparison: Head-to-Head
Knowing the individual strengths of each framework is only half the story. When teams are actually choosing between options, the differences only become clear side by side. The following comparison covers the seven dimensions that matter most for production deployments.
Architecture and Execution Model
The execution model shapes everything else: how easily workflows can be debugged, how predictably they behave, and how gracefully they handle failures.
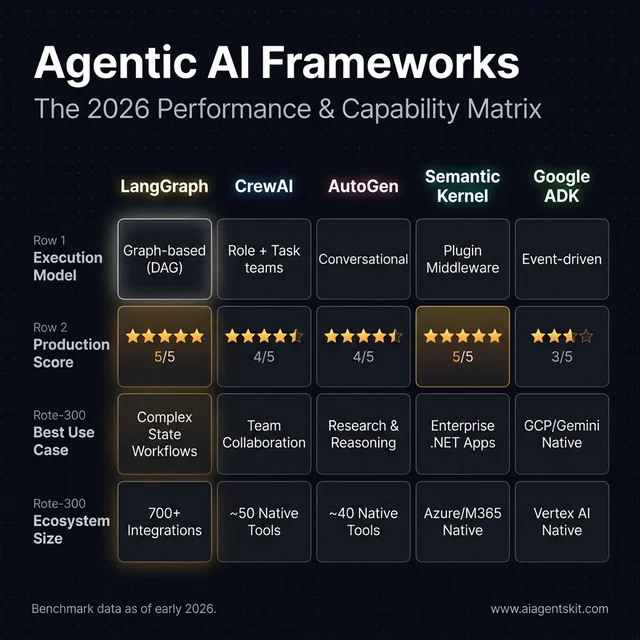
- LangGraph uses a directed acyclic graph (DAG) with explicit state management. Every edge, transition, and branch is pre-defined. This creates highly predictable, auditable behavior — the agent’s decision path can be traced step by step. Organizations using LangGraph in production report a 30% improvement in task processing efficiency from its parallelization and streaming capabilities.
- CrewAI uses a role-and-task model where agents are assigned personas and responsibilities. The mental model is intuitive, and its modular setup reduces integration overhead by approximately 25% compared to building equivalent orchestration from scratch.
- AutoGen treats agent interaction as a structured conversation. Agents reason by talking to each other — which produces excellent results through iterative critique but can be slower for tasks where speed matters more than thoroughness. Autonomous processes in AutoGen workflows can reduce overall project execution timelines by up to 30%.
- LangChain chains operations sequentially, making it easy to compose complex pipelines but less suited for non-linear workflows. Its value is its ecosystem: 700+ integrations mean teams spend less time on adapters and more on logic.
- Google ADK uses a thin abstraction layer optimized for Gemini models, making it the lowest-overhead choice for GCP-native teams.
- Semantic Kernel uses a plugin-based middleware pattern, designed to add AI capabilities to existing applications rather than build agent systems from scratch.
Full Framework Comparison Table
| Dimension | LangGraph | CrewAI | AutoGen | LangChain | Google ADK | Semantic Kernel |
|---|---|---|---|---|---|---|
| Execution model | Graph-based (DAG) | Role + task | Conversational multi-agent | Sequential chains | Event-driven | Plugin middleware |
| Execution speed | ⭐⭐⭐⭐⭐ Fastest | ⭐⭐⭐⭐ Fast | ⭐⭐⭐ Moderate | ⭐⭐⭐⭐ Fast | ⭐⭐⭐⭐⭐ Native | ⭐⭐⭐ Moderate |
| Production readiness | ⭐⭐⭐⭐⭐ Enterprise | ⭐⭐⭐⭐ AMP platform | ⭐⭐⭐⭐ v2 async | ⭐⭐⭐⭐ LTS | ⭐⭐⭐ Growing | ⭐⭐⭐⭐ Enterprise |
| Multi-agent support | ✅ Graph routing | ✅ Crew teams | ✅ Conversational | ⚠️ Limited | ✅ ADK multi-agent | ✅ Plugin agents |
| Memory & state | ✅ Checkpointing (Postgres/Redis) | ⚠️ Session-scoped | ✅ Message history | ✅ Vector + buffer | ✅ Vertex AI memory | ✅ Semantic cache |
| Human-in-the-loop | ✅ Built-in interrupts | ⚠️ Configurable | ✅ Mid-execution pause | ⚠️ Manual | ⚠️ Configurable | ✅ Filter-based |
| Integrations | 700+ (via LangChain) | ~50 native | ~40 native | 700+ | GCP/Gemini native | Azure/M365 native |
| Learning curve | ⭐⭐⭐ Steep | ⭐⭐⭐⭐⭐ Intuitive | ⭐⭐⭐ Moderate | ⭐⭐⭐⭐ Moderate | ⭐⭐⭐ GCP expertise needed | ⭐⭐⭐ .NET expertise |
| Open source | ✅ Apache 2.0 | ✅ MIT | ✅ MIT | ✅ MIT | ✅ Apache 2.0 | ✅ MIT |
| Best LLM support | Any (multi-model) | Any (multi-model) | GPT/Azure + any | Any (700+ integrations) | Gemini-optimized | OpenAI + Azure |
| GitHub stars (early 2026) | 12k+ | 28k+ | 35k+ | 95k+ | 8k+ | 22k+ |
When Does Each Framework Underperform?
Being honest about weaknesses helps teams avoid the frustration of choosing a framework that works great in tests but breaks down in production:
- LangGraph underperforms when teams need to move fast on simple tasks. The graph construction overhead is significant for straightforward pipelines that don’t need conditional branching.
- CrewAI struggles with tightly interdependent workflows that require memory across tasks. If agents need to share context at a granular level across long sessions, the session-scoped memory becomes a limitation.
- AutoGen is the slowest option for tasks where speed matters more than quality improvement through iteration. Its conversation-first approach generates significantly more tokens per task than pre-planned alternatives, which raises costs at scale.
- LangChain handles sequential chains well but becomes increasingly complex to debug as pipeline depth grows. The framework’s breadth is both its greatest strength and its primary source of configuration confusion.
- Google ADK has limited community resources and fewer third-party integrations outside the GCP/Gemini ecosystem. Teams without GCP infrastructure find little reason to choose it over better-documented alternatives.
- Semantic Kernel is .NET-first, making it an awkward fit for Python-first teams. Its enterprise middleware role means it excels at connecting AI to existing apps but is less suited to building agent-native workflows.
Real-World Agentic AI Framework Examples
The most instructive way to understand framework selection is through concrete production deployments. The following examples represent documented, verifiable implementations across six industries — not vendor case studies, but engineering decisions teams made and outcomes they measured.
LangGraph in Production: Financial Services and Customer Platforms
LinkedIn, Uber, and Replit have each confirmed LangGraph usage in production engineering workflows. The common thread: all three needed reliable, stateful pipelines where failures needed to be recoverable without restarting from scratch.
In financial services, firms are using LangGraph to build automated compliance monitoring agents — workflows that ingest regulatory change events, compare them against internal policies, flag discrepancies, and generate structured review reports. The graph architecture is ideal here because compliance decisions require strict auditability: regulators need to see exactly what the agent evaluated and why it flagged a given item. LangGraph’s state checkpointing satisfies that audit requirement natively.
One Dutch insurer documented automating 91% of motor claims using an AI agent built on a graph-based orchestration model — filing, evidence review, and initial payout decision handled end-to-end for the majority of cases, with human review triggered only when anomaly scores exceeded thresholds.
CrewAI in Production: Content, Research, and Sales Pipelines
CrewAI’s fastest adoption has come from content-intensive and research-heavy organizations where the team metaphor maps cleanly onto the actual workflow. A typical content production crew includes a Researcher (web search + summarization), Writer (drafts based on research), Editor (quality review), and SEO Analyst (keyword and structure optimization) — each as a separate agent with a defined backstory, goal, and tools.
Marketing agencies running this architecture report production throughput of high-quality drafts in 15–20 minutes versus 4–6 hours for human-only workflows. The economics are striking enough that several boutique agencies have restructured their core content process around CrewAI crews with human editors reviewing final output.
For B2B sales teams, CrewAI is powering lead qualification + outreach pipelines: a prospecting agent finds targets, an enrichment agent pulls firmographics and contact data, a personalization agent drafts outreach, and a scheduling agent books meetings. The role clarity prevents the overlapping-responsibility failures that can cause simpler multi-agent setups to generate inconsistent outputs.
AutoGen in Production: Code Review and Enterprise Reasoning
Microsoft’s internal teams use AutoGen for developer toolchain tasks — code review automation, documentation generation, and test coverage analysis. The conversational model works well here because code quality genuinely benefits from multiple perspectives: one agent proposes changes, another critiques them, a third checks for security issues.
Semiconductor and engineering firms have deployed AutoGen-based agents for research report synthesis — an agent reads papers, another summarizes key findings, a third identifies gaps and proposes follow-up questions. Research teams report compressing literature review tasks from days to hours.
Genentech’s research agents — which use an AutoGen-adjacent conversational architecture — automate literature searches that previously consumed significant researcher time. By breaking complex research questions into collaborative sub-tasks across specialized agents, they compress weeks of hypothesis exploration into days, with documented improvements in the breadth of sources reviewed.
LlamaIndex in Production: Enterprise Knowledge Applications
LlamaIndex has become the default choice for organizations deploying internal knowledge assistants — agents that need to answer questions across thousands of proprietary documents with high accuracy.
One enterprise technology firm deployed a knowledge agent across 50,000+ engineering documents, support tickets, and runbooks. LlamaIndex’s 160+ data connectors made ingestion feasible without custom ETL development. The retrieval quality — measured as first-response accuracy without human escalation — reached 84% within six weeks of tuning, versus 51% using simpler keyword search.
Law firms are using LlamaIndex-powered agents for contract review: the agent extracts obligations, deadlines, and risk clauses from documents, cross-references them against a clause library, and produces structured risk reports. The document retrieval quality is critical — missing an indemnification clause in a large contract is a material error that simpler vector search architectures produce more frequently than LlamaIndex’s specialized indexing.
Industry Metrics Worth Knowing

McKinsey’s 2026 data on agentic AI deployment shows consistent patterns across industries: teams using agent frameworks in production report 30–50% reductions in decision latency and 60–90% faster resolution times in customer-facing workflows. Manufacturing deployments using agentic frameworks for supply chain optimization have achieved 20–40% improvements in workflow speed. Gartner’s projections point to agentic AI autonomously resolving 80% of common customer service issues by 2028, cutting operational costs by 30%.
These numbers reflect real production deployments, not benchmarks. The variance is high — the teams achieving the best results have invested in observability, error handling, and domain-specific prompt engineering on top of the framework. The framework is the foundation; the quality of what’s built on top determines actual performance.
How to Choose the Right Agentic AI Framework
Selecting an agentic AI framework is less about finding the “best” option and more about finding the best fit. Practitioners consistently find that teams which research the decision thoroughly tend to refactor significantly less six months later.
According to a PwC 2025 survey, 79% of companies were adopting AI agents, with 88% planning to increase AI investment — but adoption speed doesn’t guarantee adoption quality. Many teams pick frameworks based on popularity rather than fit. The resulting mismatches are a primary driver of abandoned agentic AI projects.
When comparing AI agent frameworks, a structured evaluation against these criteria typically clarifies the decision:
Decision Framework by Use Case:
| Use Case | Recommended Framework |
|---|---|
| Rapid prototyping with tools + LLMs | LangChain |
| Complex, stateful production workflows | LangGraph |
| Role-based multi-agent teams | CrewAI |
| Conversational multi-agent collaboration | AutoGen |
| Gemini-native, GCP deployment | Google ADK |
| Azure/Microsoft enterprise environment | Semantic Kernel + AutoGen |
| Data-intensive RAG, knowledge agents | LlamaIndex |
| Mixing frameworks in same pipeline | LangChain + LlamaIndex or CrewAI |
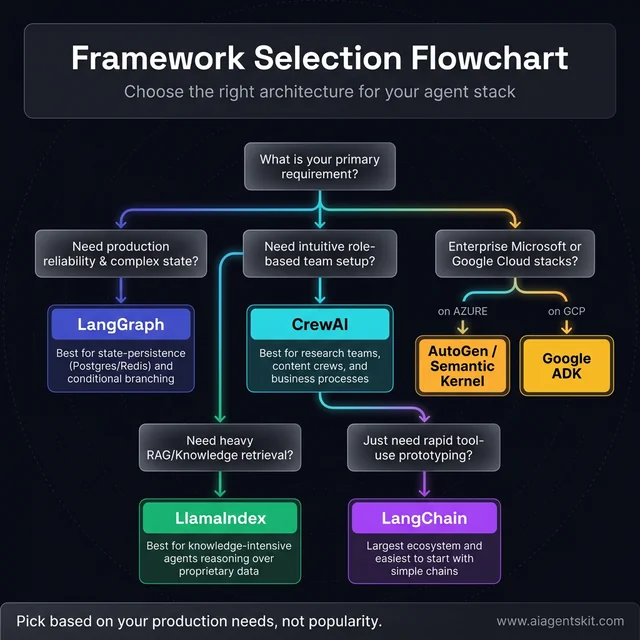
Beyond use case, five additional criteria shape the decision:
Workflow complexity: Linear, sequential tasks suit CrewAI or LangChain. Workflows with conditional branching, error recovery, and non-linear state transitions need LangGraph or AutoGen.
Team technical depth: LangGraph rewards engineering investment with control and reliability. CrewAI offers a more intuitive entry point for teams building their first multi-agent system. The best framework is one the team can debug when something goes wrong.
Existing infrastructure: Azure-first organizations benefit from AutoGen/Semantic Kernel’s native integrations. GCP shops benefit from Google ADK. Cloud-agnostic teams have more flexibility — and vendor lock-in risk is real regardless of which direction is chosen.
Production vs. prototype timeline: For proof-of-concept, any framework works. For production, observability tooling (LangSmith, AutoGen Studio), error handling, and checkpointing become critical requirements that eliminate several otherwise capable options.
Open source vs. managed: Open-source frameworks offer flexibility and community; managed platforms offer support and reduced operational overhead. Many teams start with the former and shift to the latter as usage scales.
What Are the Biggest Challenges With Agentic AI?
Agentic AI frameworks unlock significant capabilities, but practitioners evaluating AI agent use cases encounter consistent friction points that deserve honest assessment.
The most frequently cited challenge is reliability in multi-step workflows. Individual LLM calls have error rates that, when chained across 5, 10, or 20 steps, compound quickly. A framework that doesn’t include retry logic, error recovery, and fallback mechanisms will produce brittle pipelines that fail at exactly the moment you need them most.
Memory and context management at scale remains genuinely hard. Even Claude 4’s 200K-token context window creates challenges for truly long-running agentic tasks — what happens when an agent’s accumulated context exceeds the model’s limit? Most frameworks have mechanisms, but none of them are seamless. This is an area where even experts disagree about the right architectural approach.
Cost at scale surprises teams that prototype on small workloads. Agentic loops generate significantly more tokens than single-call queries. A workflow that costs pennies in testing can accumulate dollars in production once token consumption from reasoning, tool calls, retries, and summarization is accounted for.
Observability gaps make debugging agentic systems genuinely difficult. “Why did the agent take that action?” is a question that’s hard to answer without comprehensive tracing. LangSmith, AutoGen Studio, and CrewAI AMP have made progress here, but it remains a weaker area compared to conventional software debugging.
Safety and guardrails at the framework level are still immature. Preventing agents from taking harmful or unintended actions — particularly when they have access to file systems, databases, or external APIs — requires careful design that most frameworks leave largely to the developer. Gartner has noted that the supply of agentic AI models is beginning to exceed enterprise demand for fully autonomous systems, citing governance concerns as a primary driver of caution.
According to McKinsey’s 2025 workplace AI report, only about 1% of companies feel mature in their agentic AI implementations — suggesting the gap between deployment and mastery remains substantial. That’s not a reason to delay, but it is a reason to architect carefully.
Agentic AI Frameworks: Frequently Asked Questions
What is an agentic AI framework?
An agentic AI framework is a software toolkit designed to build autonomous AI systems that can plan, reason, use tools, and take multi-step actions toward a goal without requiring explicit human instruction at each step. These frameworks handle the infrastructure that connects large language models to the real world — including tool integrations, memory management, agent orchestration, and control logic. They differ from simple chatbot frameworks in their support for multi-step loops, state persistence, and inter-agent communication.
How do agentic AI frameworks differ from traditional machine learning pipelines?
Traditional ML pipelines are deterministic and static: data flows through a fixed sequence of transformation steps with predictable inputs and outputs. Agentic AI frameworks support dynamic, adaptive execution — an agent can observe intermediate results, change its approach, call different tools, and iterate until a goal is met. Traditional pipelines optimize for batch processing efficiency. Agentic frameworks optimize for flexible, goal-directed action in conditions that weren’t fully anticipated at design time.
What is the best agentic AI framework for beginners?
For developers new to agentic AI, LangChain offers the most comprehensive documentation, tutorials, and community support. Its modular design makes it straightforward to start with simple chains and gradually add complexity. CrewAI is an excellent second choice — its role-based mental model is particularly intuitive for teams coming from a workflow or process automation background. Both frameworks have active communities and extensive open-source examples to learn from.
Can multiple agentic AI frameworks be used together?
Yes, and many production teams do exactly that. A common combination in 2026 is using LangChain for tool management and retrieval (especially alongside LlamaIndex for knowledge-intensive components) while using CrewAI or AutoGen for multi-agent orchestration. The frameworks are generally compatible at the API level, though integrating them requires careful state management to avoid context conflicts. Teams that combine frameworks typically do so because no single framework covers all their requirements equally well.
How does LangGraph differ from LangChain for agent development?
LangChain provides the building blocks: model wrappers, tool integrations, prompt templates, and chain composition. LangGraph adds a graph-based orchestration layer on top. In LangGraph, workflows are defined as directed graphs where nodes represent actions or decisions and edges represent transitions. This enables cycles, conditional branching, and non-linear execution flows that standard LangChain chains — which execute linearly — can’t model. For simple agents, LangChain is sufficient. For complex, stateful, production workflows, LangGraph is the necessary upgrade.
What role does human-in-the-loop play in agentic AI systems?
Human-in-the-loop (HITL) controls are approval gates that pause agent execution and require human review before proceeding. They’re critical for high-stakes or irreversible actions — submitting a contract, deleting data, sending a customer email. In practice, most production agentic systems use HITL selectively: fully autonomous for low-risk, routine actions and human-supervised for anything with significant consequences. For regulated industries (healthcare, finance, legal), HITL isn’t optional — it’s a compliance requirement that frameworks must support architecturally.
Are agentic AI frameworks production-ready in 2026?
Select frameworks are demonstrably production-ready in 2026. LangGraph, with built-in checkpointing and observability through LangSmith, is in production at major technology companies. AutoGen v2’s async event-driven architecture and Azure AI Foundry integration make it viable for enterprise production workloads. CrewAI AMP adds the monitoring and scaling infrastructure needed for production environments. That said, “production-ready framework” doesn’t mean production-ready agents automatically — reliability still depends heavily on the quality of the prompts, tools, and guardrails the team builds on top.
What are the security risks of deploying agentic AI frameworks?
The primary security risks in agentic AI are prompt injection (malicious inputs that hijack agent behavior), uncontrolled tool access (agents calling APIs or running code beyond their intended scope), and data leakage (agents inadvertently exposing sensitive information to external services). Frameworks mitigate these differently — some provide built-in sandboxing for code execution, others rely on developer-configured access controls. Defense in depth matters: tool permissions should follow the principle of least privilege, and all external tool calls should be logged for audit review.
How do agentic AI frameworks handle long-running tasks?
Long-running tasks present a fundamental challenge: how to preserve agent state across hours, days, or interruptions without re-running expensive computation. The leading approach is checkpointing — periodically saving agent state (including conversation history, intermediate results, and tool outputs) to a persistent store. LangGraph’s checkpoint system stores state in various backends (SQLite, Redis, Postgres). AutoGen’s event-driven architecture handles task suspension and resumption natively. Caching tool outputs, rather than re-executing tool calls on resume, is another cost-saving pattern that mature frameworks support.
The Agentic AI Framework Landscape Is Still Evolving
The agentic AI framework ecosystem has matured faster than most expected, but the landscape is far from settled. A year ago, the conversation was about whether agentic systems were ready for production. Today, the conversation is about which framework fits which workload — a sign of genuine category maturation. And yet consolidation is still ahead: some frameworks that are relevant today will merge, be acquired, or fade as enterprise standards emerge.
The data supports the pace of change: Precedence Research projects the agentic AI market at $10.86 billion in 2026, growing at a 43.84% CAGR to reach $199 billion by 2034. That trajectory puts agentic AI infrastructure investment in roughly the same category as cloud infrastructure investment in the early 2010s — a period when the right technical bets compounded significantly.
Gartner’s caution about oversupply is worth noting: as more teams ship agentic capabilities, the bar for what qualifies as “production-grade” keeps rising. The frameworks winning enterprise adoption right now — LangGraph, AutoGen v2, CrewAI AMP — are doing so because they’ve invested in the operational concerns that matter in messy real-world deployments: monitoring, error recovery, state management, and governance controls. Popularity alone isn’t sustainable in production environments.
For teams choosing a framework now, the practical advice from practitioners who’ve shipped production agentic systems is consistent: start with the framework that matches the immediate use case, not the one with the most features. Complexity should grow in response to actual requirements, not anticipated ones. For most teams, that means starting with LangChain or CrewAI, moving to LangGraph as workflow complexity grows, and integrating LlamaIndex when data retrieval quality becomes the binding constraint.
The AI agent space is moving fast enough that the frameworks available today may look materially different twelve months from now. That argues for choosing frameworks with strong open-source communities and modular architectures over tightly coupled proprietary platforms — the flexibility to adapt matters when underlying model capabilities are still improving at the current rate.
Those just getting started can build your first AI agent in Python with a minimal LangChain implementation — a working agent with tool access can be running in an afternoon. For teams already past the prototype stage, the frameworks and decision criteria covered here map directly to the architectural choices that determine whether the agentic investment delivers real production value or becomes another AI pilot that never scales.